
聊一聊Normalization and Standardization
什么是
Normalization就是归一化,是最小-最大缩放(min-max scaling)的特例,指的是将数据缩放到指定range,这个range通常是01或者-1+1,直观来讲就是下图,在数据不包含离群点时很有用,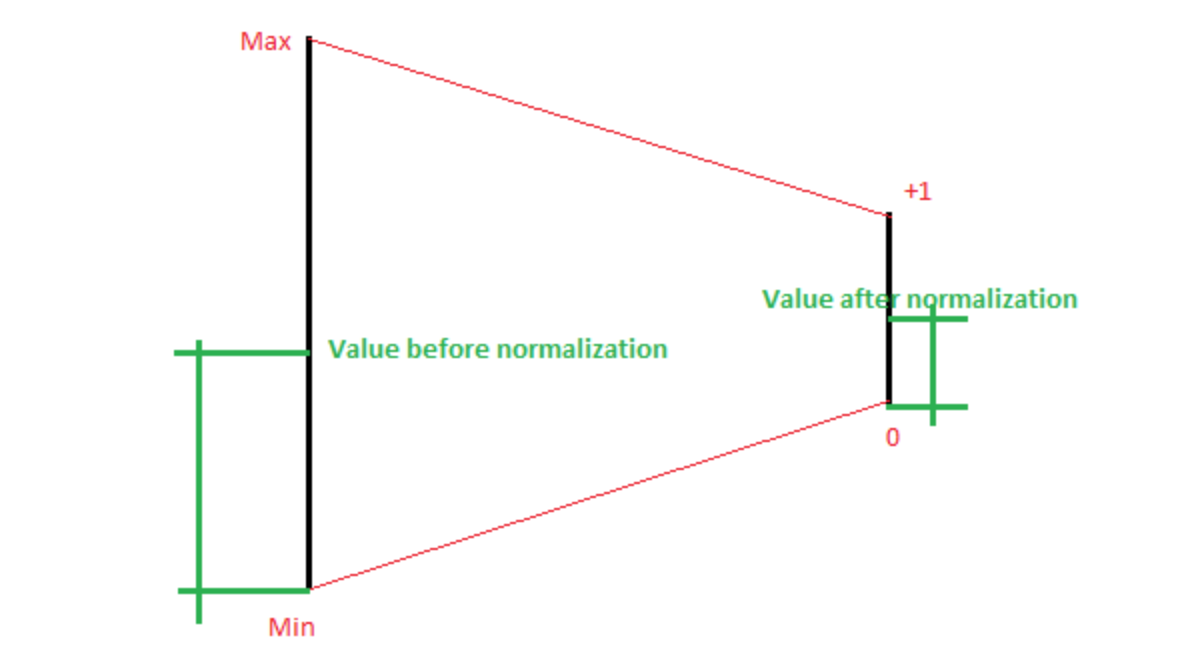
公式则是
$$
x^{(i)}{norm} = \frac {x^{(i)} - x{min}} {x_{max} - x_{min}}
$$
若要缩放至-1~+1,则是
$$
x’ = \frac{x - min}{max - min}
$$
代码实现
1 | #导入数据预处理库 |
1 | #测试集缩放标准化 |
Z-score 标准化指的是,通过缩放让数据的均值为0(移除均值),标准差为固定值(比如1)。在许多模型里,如SVM的RBF、线性模型的 L1 & L2 正则项对于所有的feature都有这样的假设。
$$
x^{(i)}_{std} = \frac{x^{(i)} - \mu_x}{\sigma_x}
$$
以下是一个简单的例子展示了两者的区别:
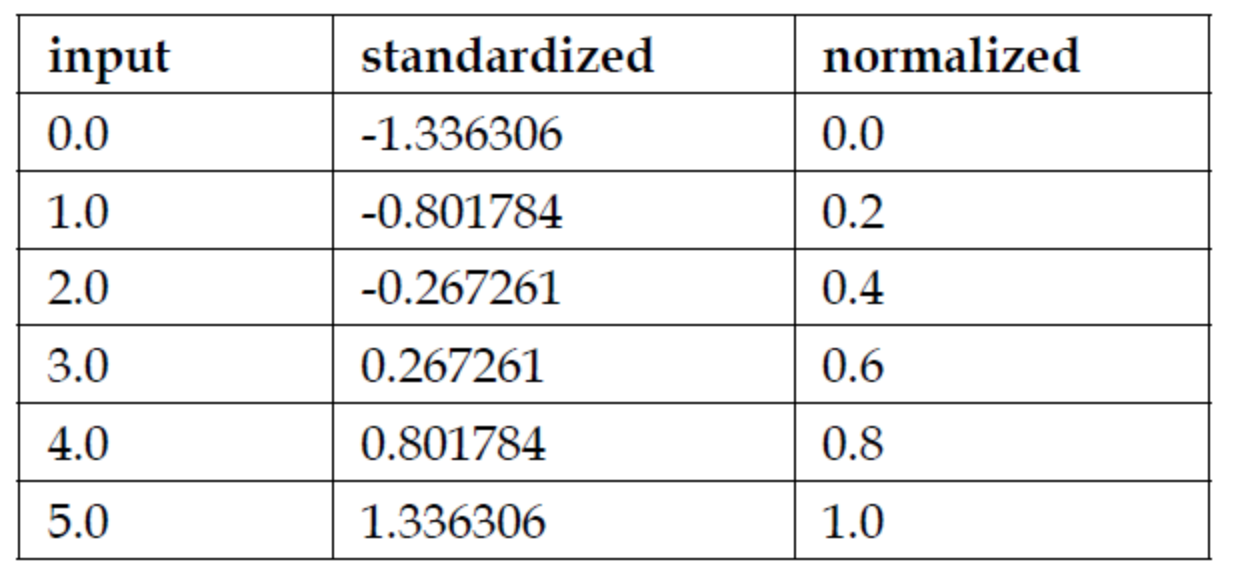
1 | #导入数据预处理库 |
同时对测试集的数据进行标准化处理,以保证训练集和测试集的变换方式相同。
1 | #测试集数据标准化 |
值得注意
从流程上讲,标准化和归一化应该在读入数据、处理缺失值,切分训练测试集之后,而且我们要做的是在切分之后,在训练集fit,再去transform测试集,而不是在整个数据上转换以后再切分,因为无论是标准化还是归一化,我们要么利用到了数据的max min值,要么利用到了数据的均值和标准差,这些数值在训练之前是不能被测试集所影响的。
类似于缺失值的填充,举个例子,我们使用均值填充以下数据,
1 | #使用均值填充缺失值 |
以同样的方式填充测试集,以保证测试集和训练集的数据填充方式保持一致。
1 | #填充测试集 |