最近学习了斯坦福的CS224d课程,该课 程的主要内容是神经网络在自然语言处理领域的应用。 这里记录相关的学习笔记,大概分 成以下几个部分:word2vec,窗口分类,神经网络,循环神经网络,递归神经网络,卷积 神经网络。
##为什么需要深度学习
传统的机器学习方法都是人为的设计特征或者表示,深度学习的目的是希望能够通过神经网络让机器自动学习到有效的特征表示,这里所说的深度学习更偏向于关注各种类型的神经网络。探索机器学习的原因主要有以下几方面:
- 人工设计的特征常常定义过多,不完整并且需要花费大量的时间去设计和验证
- 自动学习的特征容易自适应,并且可以很快的学习
- 深度学习提供了一个弹性的,通用的学习框架用来表征自然的,视觉的和语言的信息。
- 深度学习可以用来学习非监督的(来自于生文本)和有监督的(带有特别标记的文本,例如正向和负向标记)
在2006年深度学习技术开始在一些任务中表现出众,为什么现在才热起来?
- 深度学习技术受益于越来越多的数据
- 更快的机器与更多核CPU/GPU对深度学习的普及起了很大的促进作用
- 新的模型,算法和idea层出不穷
- 通过深度学习技术提升效果首先发生在语音识别和机器视觉领域,然后开始过渡到NLP领域
深度学习在所有的NLP层次(音素、形态学、句法、语义)都得到了应用,而所有的NLP层次的表示都涉及到向量(Vectors),下面主要讲如何用向量来表示词。
##词向量
###语义词典
我们要如何表示一个词的意思呢?常识上,在词典中我们通过更加简单常用的词来构成例句来解释一个词的意思。那在计算机中,我们通常使用Wordnet来表示词义:
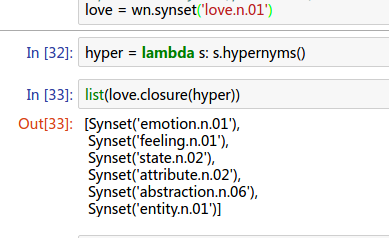
但语义词典存在如下问题:
- 语义词典资源很棒但是可能在一些细微之处有缺失,例如这些同义词准确吗:adept, expert, good, practiced, proficient,skillful?
- 会错过一些新词,几乎不可能做到及时更新: wicked, badass, nifty, crack, ace, wizard, genius, ninjia
- 有一定的主观倾向
- 需要大量的人力物力
- 很难用来计算两个词语的相似度
###One-hot Representation
首先我们把词表中的词从$$0到|V|−1$$进行编号,ont-hot向量把每个词表示成一个$$|V|$$维 (词表大小为$$|V|$$)的向量,该向量只有特定词的编号对应的位置为1,其他位置全部为0 。这种方法把每个词表示成独立的个体,无法通过one-hot向量直接表示出词之间的关系。解决方法是通过一个词的上下文来表示一个词。 例如,比如