
如图所示,利用pipeline我们可以方便的减少代码量同时让机器学习的流程变得直观,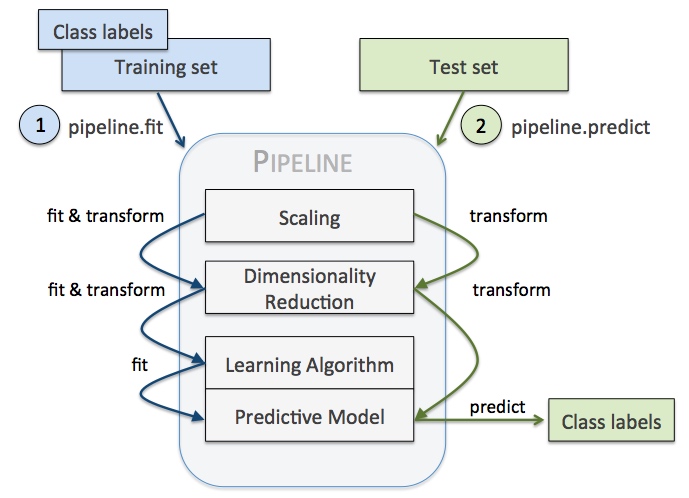
例如我们需要做如下操作,容易看出,训练测试集重复了代码,
1 | vect = CountVectorizer() |
利用pipeline,上面代码可以抽象为,
1 | pipeline = Pipeline([ |
注意,pipeline最后一步如果有predict()方法我们才可以对pipeline使用fit_predict(),同理,最后一步如果有transform()方法我们才可以对pipeline使用fit_transform()方法。
使用pipeline做cross validation
看如下案例,即先对输入手写数字的数据进行PCA降维,再通过逻辑回归预测标签。其中我们通过pipeline对
PCA的降维维数n_components和逻辑回归的正则项C大小做交叉验证,主要步骤有:
- 依次实例化各成分对象如
pca = decomposition.PCA() - 以(name, object)的tuble为元素组装pipeline如
Pipeline(steps=[('pca', pca), ('logistic', logistic)]) - 初始化CV参数如
n_components = [20, 40, 64] - 实例化CV对象如
estimator = GridSearchCV(pipe, dict(pca__n_components=n_components, logistic__C=Cs)),其中注意参数的传递方式,即key为pipeline元素名+函数参数
1 | import numpy as np |
自定义transformer
我们可以如下自定义transformer(来自Using Pipelines and FeatureUnions in scikit-learn - Michelle Fullwood)
1 | from sklearn.base import BaseEstimator, TransformerMixin |
另外,我们也可以对每个feature单独处理,例如下面的这个比较大的流水线(来自Using scikit-learn Pipelines and FeatureUnions | zacstewart.com),我们可以发现作者的pipeline中,首先是一个叫做features的FeatureUnion,其中,每个特征分别以一个pipeline来处理,这个pipeline首先是一个ColumnExtractor提取出这个特征,后续进行一系列处理转换,最终这些pipeline组合为特征组合,再喂给一系列ModelTransformer包装的模型来predict,最终使用KNeighborsRegressor预测(相当于两层stacking)。
1 | pipeline = Pipeline([ |
1 | class HourOfDayTransformer(TransformerMixin): |
1 | class ModelTransformer(TransformerMixin): |
FeatureUnion
sklearn.pipeline.FeatureUnion — scikit-learn 0.19.1 documentation 和pipeline的序列执行不同,FeatureUnion指的是并行地应用许多transformer在input上,再将结果合并,所以自然地适合特征工程中的增加特征,而FeatureUnion与pipeline组合可以方便的完成许多复杂的操作,例如如下的例子,
1 | pipeline = Pipeline([ |
整个features是一个FeatureUnion,而其中的ngram_tf_idf又是一个包括两步的pipeline。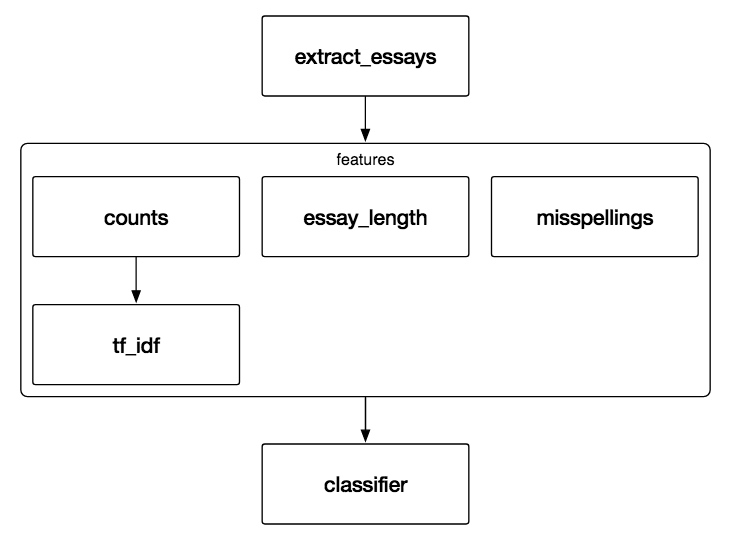
下面的例子中,使用FeatureUnion结合PCA降维后特征以及选择原特征中的几个作为特征组合再喂给SVM分类,最后用grid_search 做了 pca的n_components、SelectKBest的k以及SVM的C的CV。
1 | from sklearn.pipeline import Pipeline, FeatureUnion |