Pycharm Pro

Pycharm,只为提高python开发者的生产力!
Go 语言操作与扫描 Hbase 实例


记录纯go语言的gohbase客户端的扫描操作。




服务器负载GUI 神器sargraph 的安装
通过Linux 的sar命令可以很容易知道服务器的负载,那么如何通过网页等更好地可视化呢?本文介绍实现此功能的神器SARGRAPH-Graphical front-end for sar的使用及安装。
sar的配置
通过这里我们可以看到
sar 找出系统瓶颈的利器 — Linux Tools Quick Tutorial
安装sar
- 有的linux系统下,默认可能没有安装这个包,使用apt-get install sysstat 来安装;
- 安装完毕,将性能收集工具的开关打开: vi /etc/default/sysstat
- 设置 ENABLED=”true”
- 启动这个工具来收集系统性能数据: /etc/init.d/sysstat start
避免 spark 提交 上传自带 jar包解决办法
1 | 17/09/01 15:38:59 INFO yarn.Client: Uploading resource file:/usr/local/spark-2.1.1-bin-without-hadoop/spark-46d1bd70-b346-4027-bce4-9540f4b6035a/__spark_libs__4051900056689219834.zip -> hdfs://wwj.shise.com:9000/user/hadoop/.sparkStaging/application_1504148698505_0021/__spark_libs__4051900056689219834.zip |
可以看到,上传花费约3分钟,这段时间是为了将$SPARK_HOME/jar下的所有jar包上传到yarn,实际上可以完全避免。
实际上这部分文件完全可以就放在hdfs上,
先将这部分jar包复制到hdfs:
hadoop fs -mkdir /tmp/spark/lib_jars/
hadoop fs -put $SPARK_HOME/jars/* /tmp/spark/lib_jars/
设置vim $SPARK_HOME/conf/spark-defaults.conf:
添加这行
1 | spark.yarn.jars /tmp/spark/lib_jars/* ##这里用hdfs相对路径即可 |
再submit不会出现将jar文件打包成zip文件上传的信息了。
hbase rest 绑定到内网localhost
通过开启Hbase 的REST 服务我们可以很方便的以API的形式访问Hbase,
1 | # Foreground |
但是其默认是绑定0.0.0.0地址的,也就是对外网开放,而通过REST 服务别有用心的人是可以删表的。。。如何只对内网开放呢?
查了无数中英文网页不得,最后决定:看源码!最后在这里发现如下片段,hbase/RESTServer.java at master · apache/hbase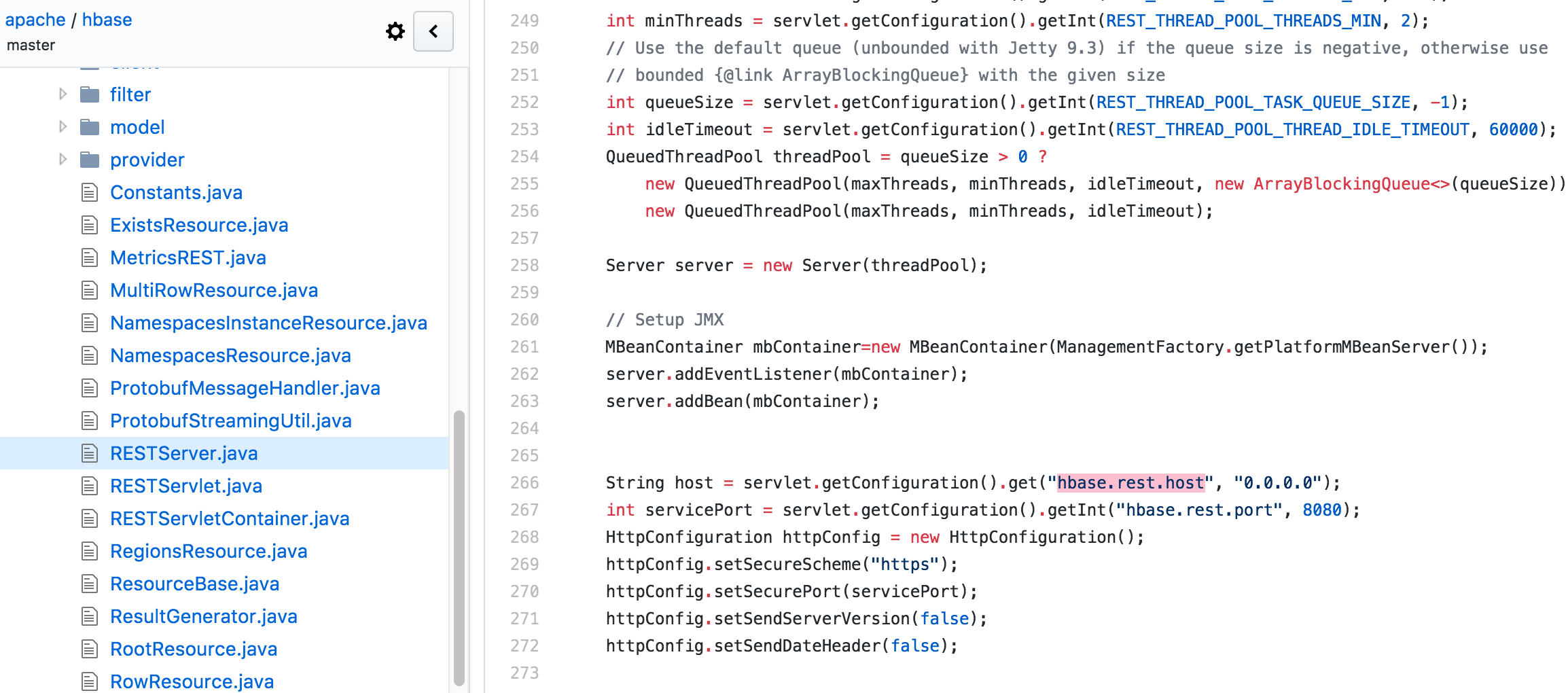
那么解决方法就显而易见了:
1 | # sudo vim /usr/local/hbase/conf/hbase-site.xml |
scala-notes
call by name 与 call by value的区别
两者的区别就是调用之前需不需要evaluation,前者不需要,后者需要。例如一个函数$f(x, y) = x$,我们分别调用$f(1+1, 2 )$,call by name 直接引用1+1,再计算出为2,而 call by value是先算出函数参数的值,再去调用$f(2, 2 )$,scala默认是call by value,但是可以在需要call by name 的参数加箭头如=>。
scala里面定义变量def和val的区别即在此,前者是call by name,例如我们分别定义两个函数:
1 | def loop: Boolean = loop |
函数x可以被成功定义,而后者不行,因为在call by name 的参数evaluation的时候就进入死循环了。