def_kl_divergence(params, P, degrees_of_freedom, n_samples, n_components, skip_num_points=0): """t-SNE objective function: gradient of the KL divergence of p_ijs and q_ijs and the absolute error.""" X_embedded = params.reshape(n_samples, n_components)
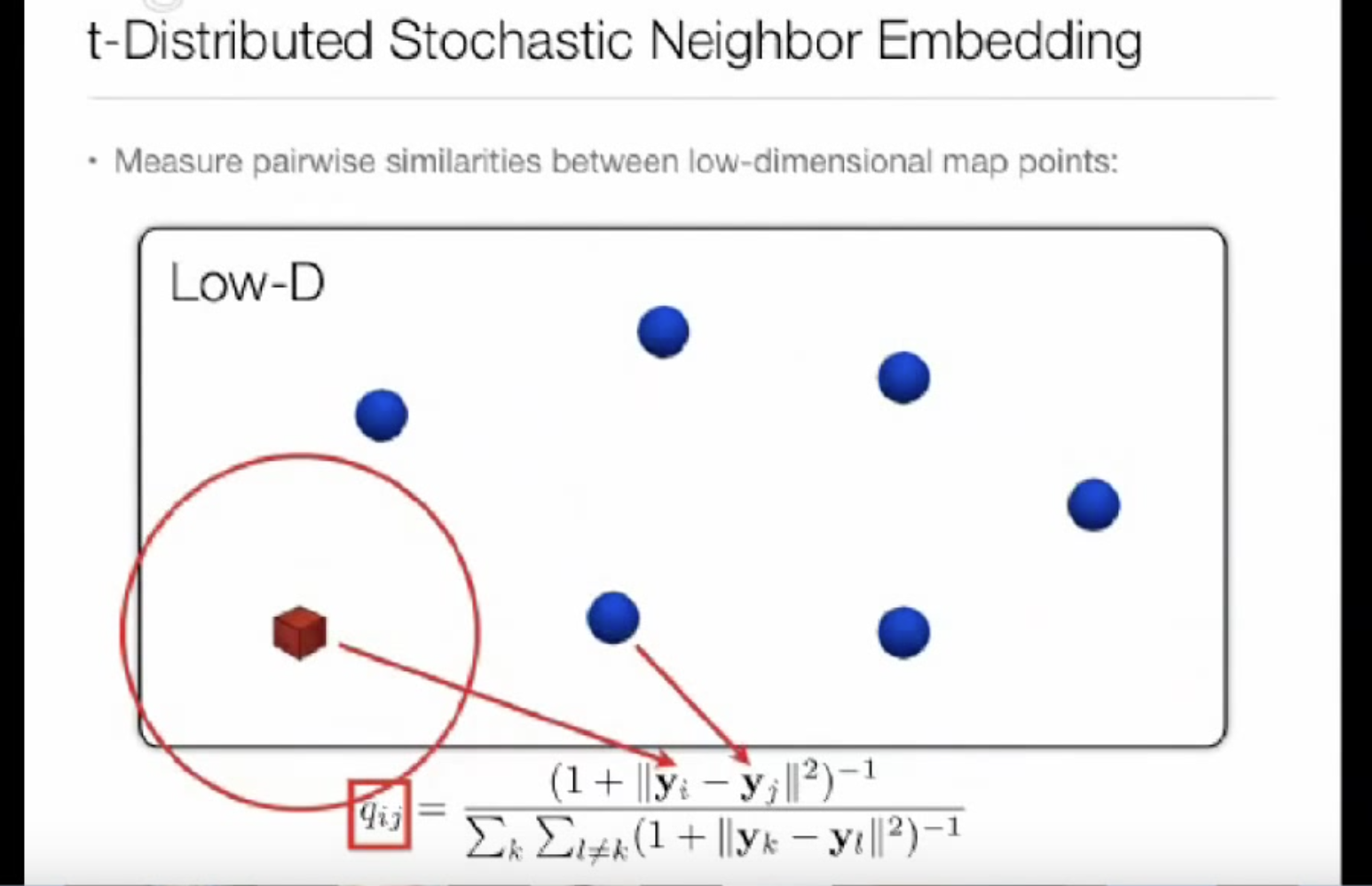
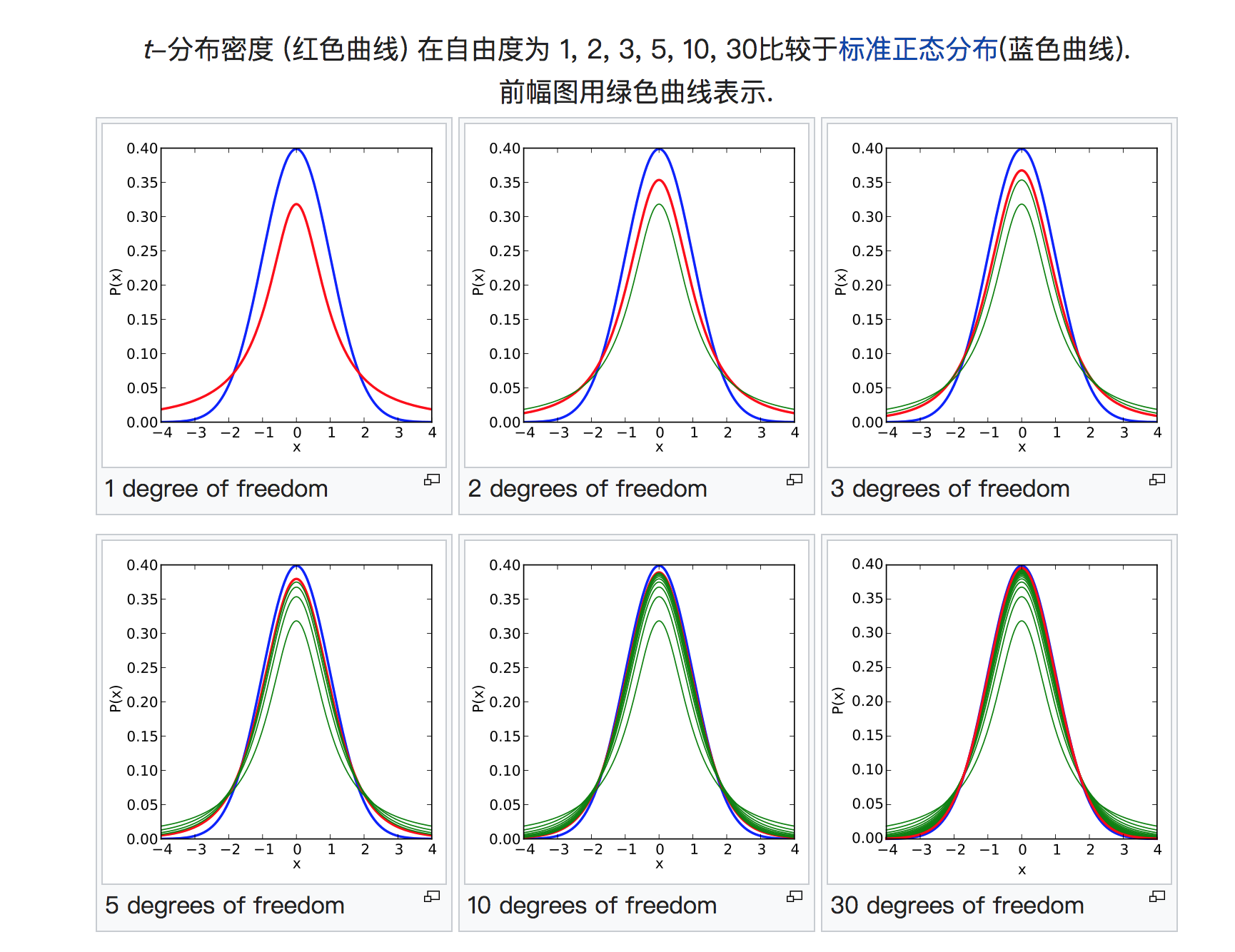
# Q is a heavy-tailed distribution: Student's t-distribution n = pdist(X_embedded, "sqeuclidean") n += 1. n /= degrees_of_freedom n **= (degrees_of_freedom + 1.0) / -2.0 Q = np.maximum(n / (2.0 * np.sum(n)), MACHINE_EPSILON)
# Optimization trick below: np.dot(x, y) is faster than # np.sum(x * y) because it calls BLAS
# Objective: C (Kullback-Leibler divergence of P and Q) kl_divergence = 2.0 * np.dot(P, np.log(P / Q))
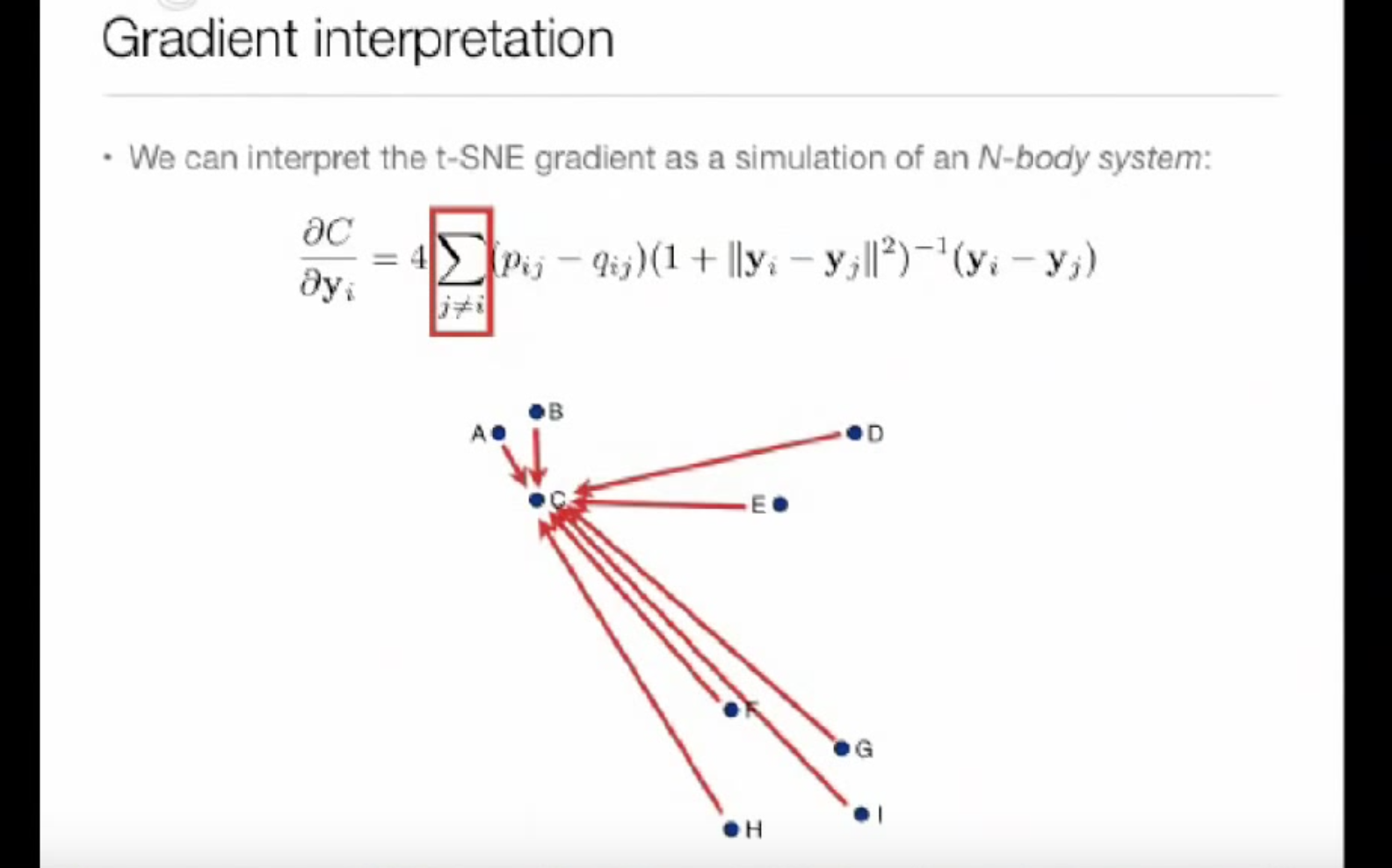
# Gradient: dC/dY grad = np.ndarray((n_samples, n_components)) PQd = squareform((P - Q) * n) for i inrange(skip_num_points, n_samples): np.dot(_ravel(PQd[i]), X_embedded[i] - X_embedded, out=grad[i]) grad = grad.ravel() c = 2.0 * (degrees_of_freedom + 1.0) / degrees_of_freedom grad *= c
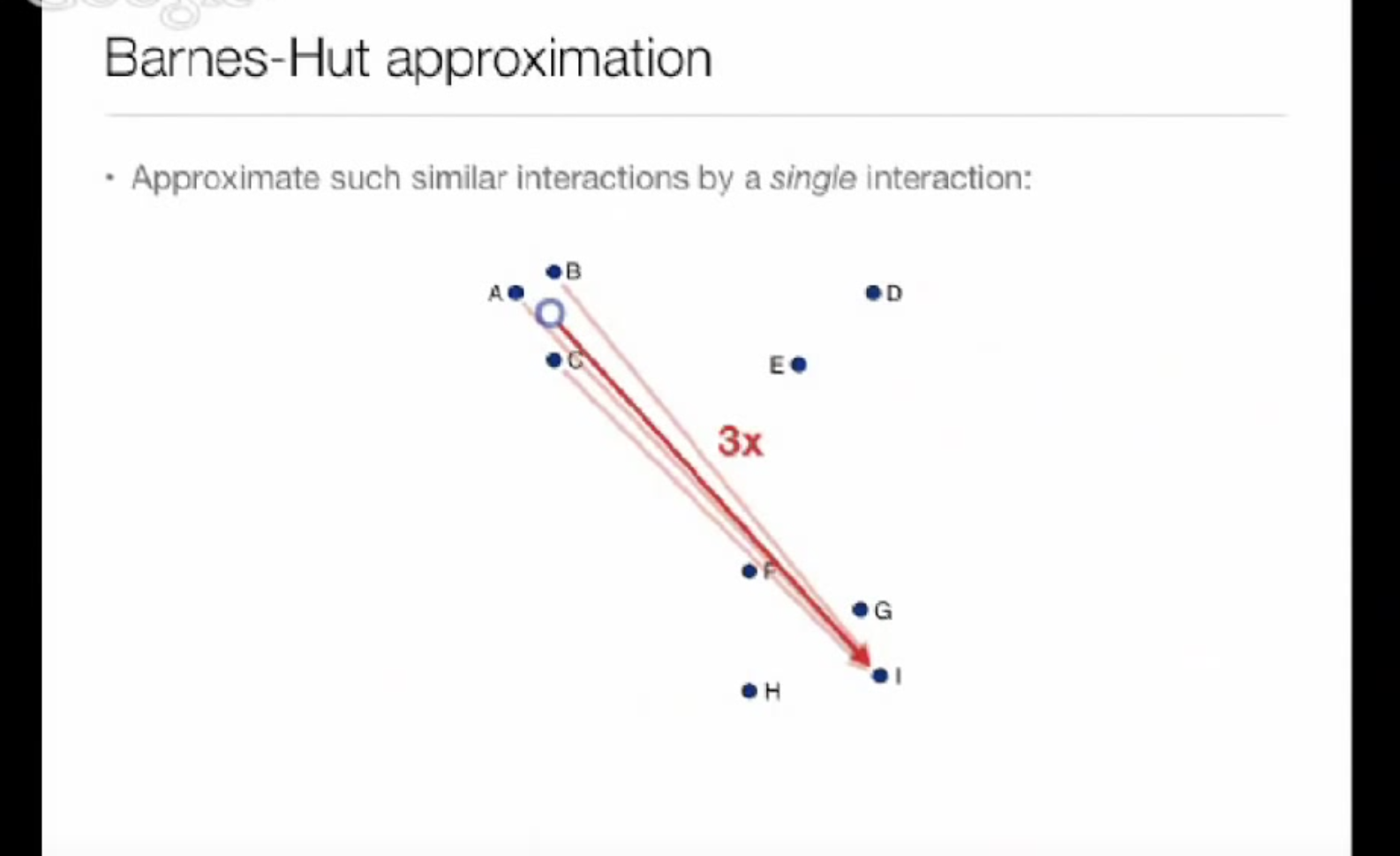
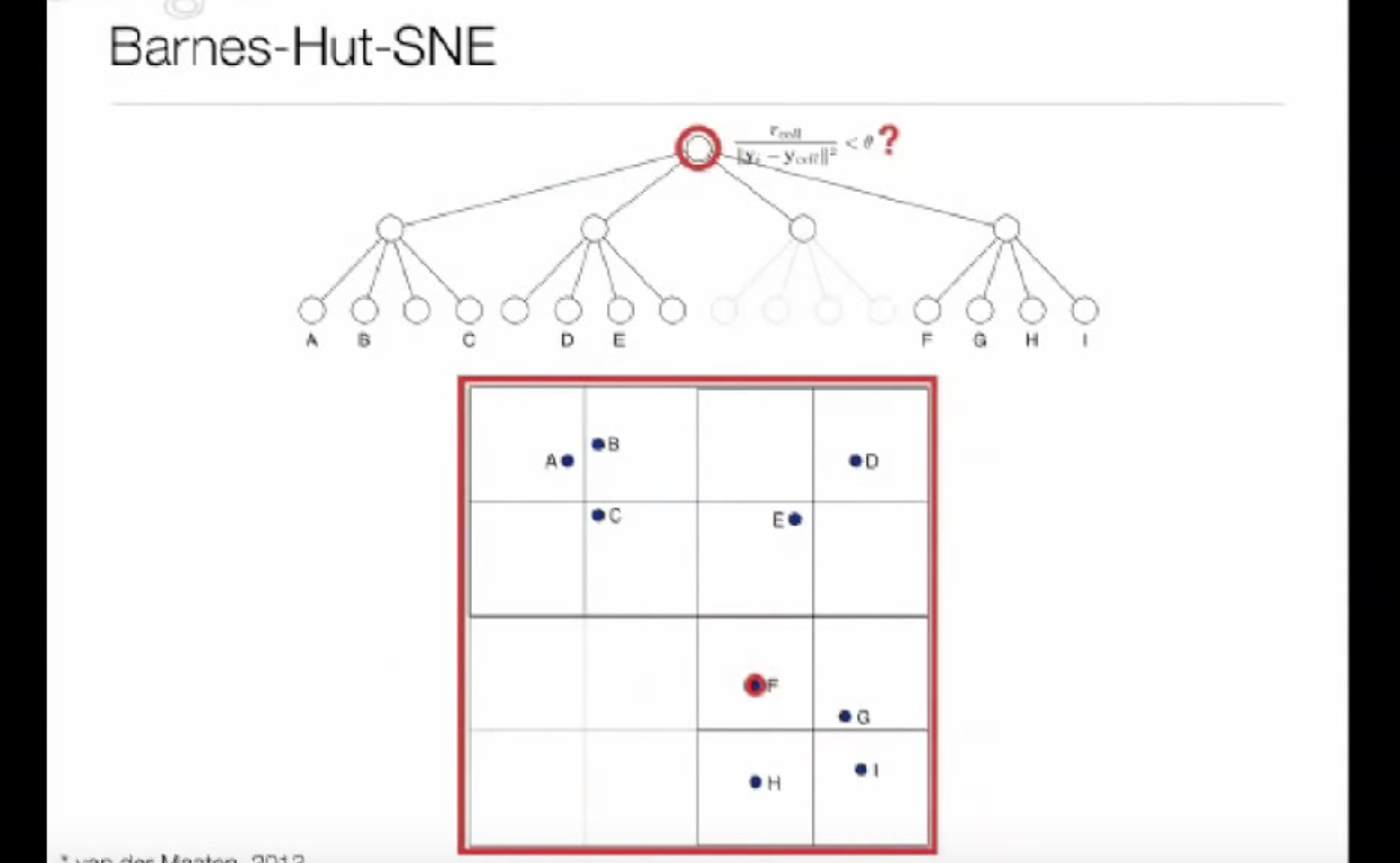
grad = np.zeros(X_embedded.shape, dtype=np.float32) error = _barnes_hut_tsne.gradient(sP, X_embedded, neighbors, grad, angle, n_components, verbose, dof=degrees_of_freedom) c = 2.0 * (degrees_of_freedom + 1.0) / degrees_of_freedom grad = grad.ravel() grad *= c