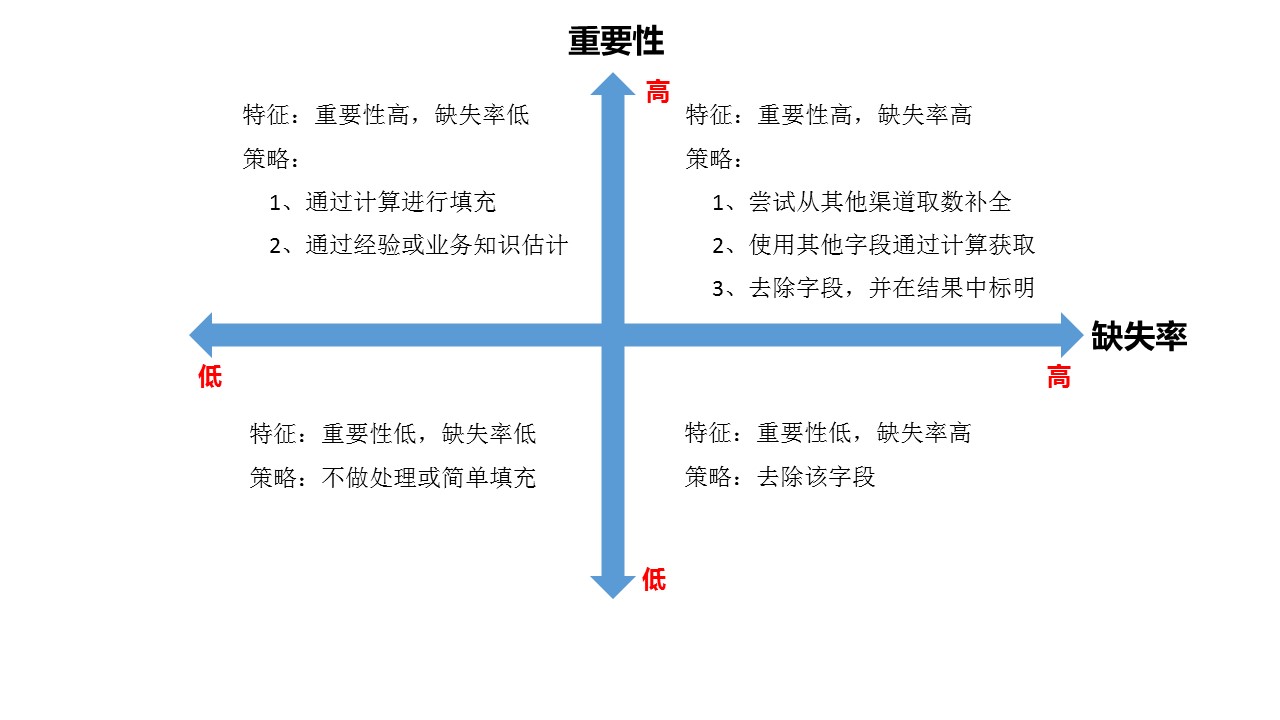
#dealing with missing data df_train = df_train.drop((missing_data[missing_data['Total'] > 1]).index,1) df_train = df_train.drop(df_train.loc[df_train['Electrical'].isnull()].index) df_train.isnull().sum().max()
离群点
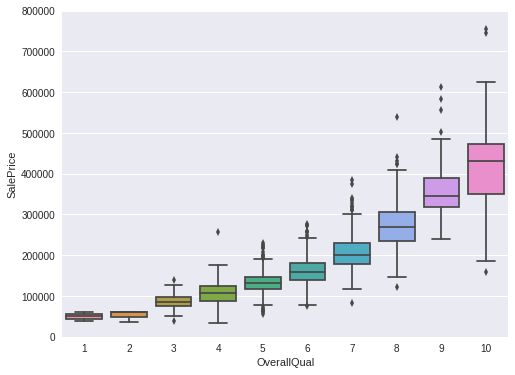
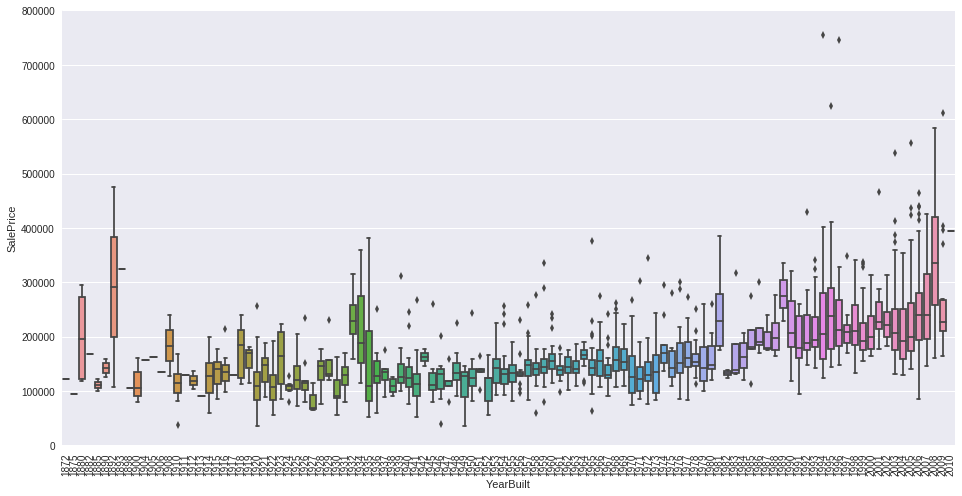
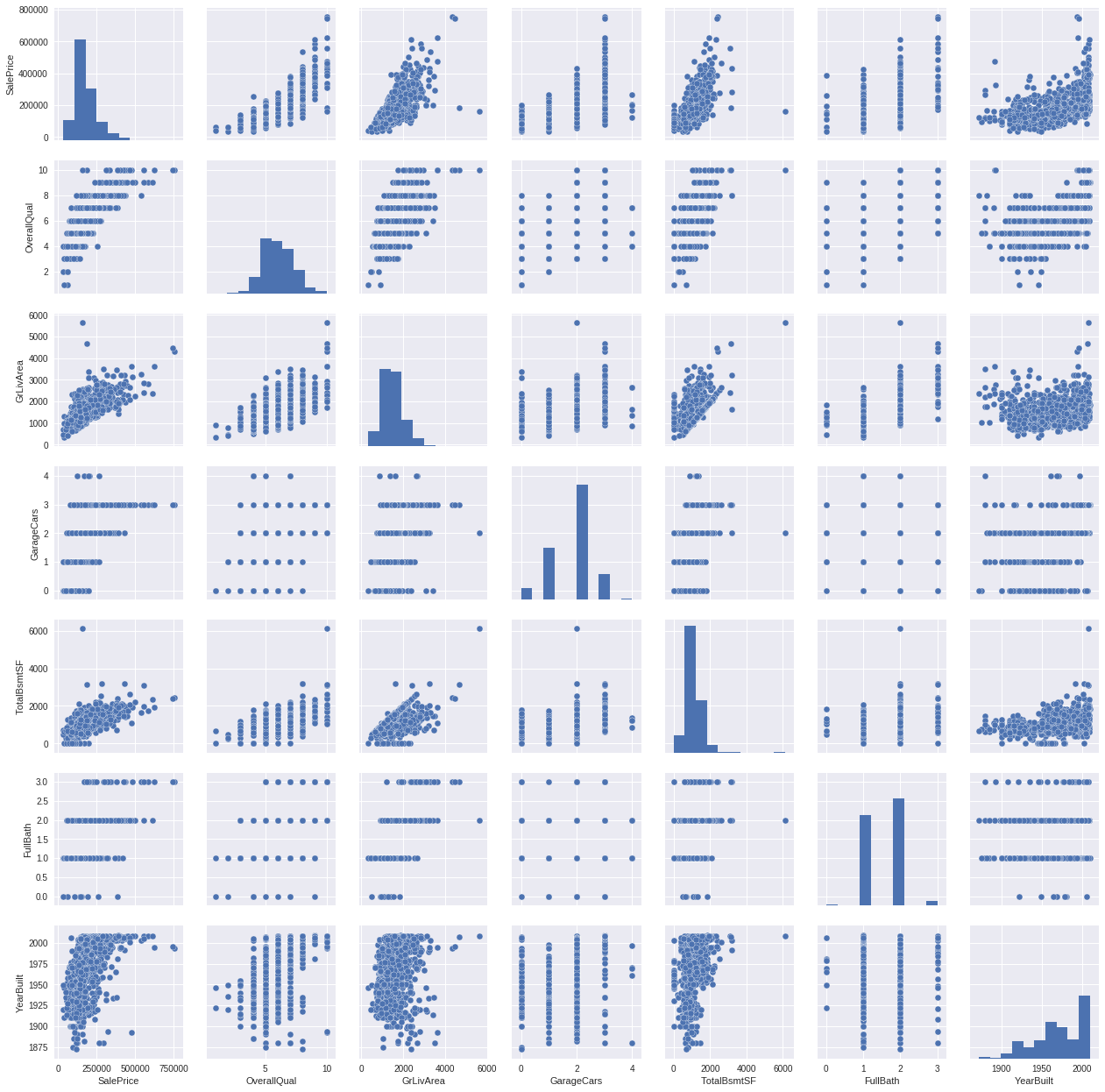
单特征情况,可以以如下形式观察
1 2 3 4 5 6 7 8
#standardizing data saleprice_scaled = StandardScaler().fit_transform(df_train['SalePrice'][:,np.newaxis]); low_range = saleprice_scaled[saleprice_scaled[:,0].argsort()][:10] high_range= saleprice_scaled[saleprice_scaled[:,0].argsort()][-10:] print('outer range (low) of the distribution:') print(low_range) print('\nouter range (high) of the distribution:') print(high_range)
outer range (low) of the distribution: [[-1.83820775] [-1.83303414] [-1.80044422] [-1.78282123] [-1.77400974] [-1.62295562] [-1.6166617 ] [-1.58519209] [-1.58519209] [-1.57269236]]
outer range (high) of the distribution: [[ 3.82758058] [ 4.0395221 ] [ 4.49473628] [ 4.70872962] [ 4.728631 ] [ 5.06034585] [ 5.42191907] [ 5.58987866] [ 7.10041987] [ 7.22629831]]
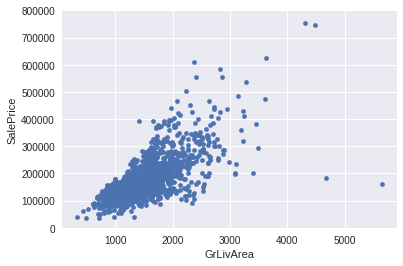
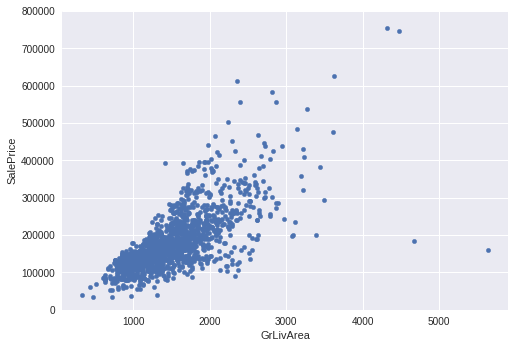
双特征关系如特征标签关系那样,先concat再scatter
1 2 3 4
#bivariate analysis saleprice/grlivarea var = 'GrLivArea' data = pd.concat([df_train['SalePrice'], df_train[var]], axis=1) data.plot.scatter(x=var, y='SalePrice', ylim=(0,800000));
离群点可以简单删去,如
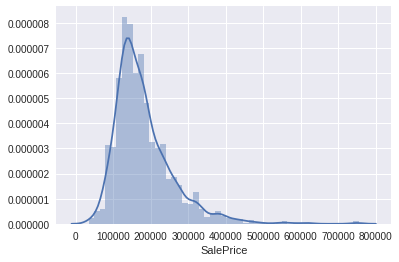
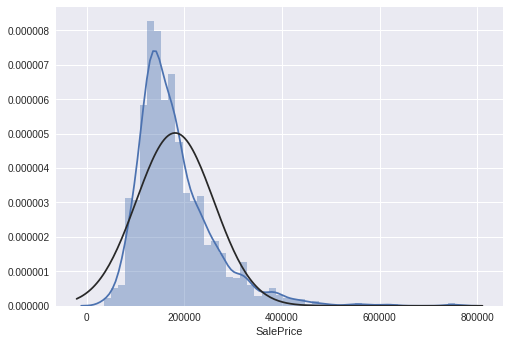
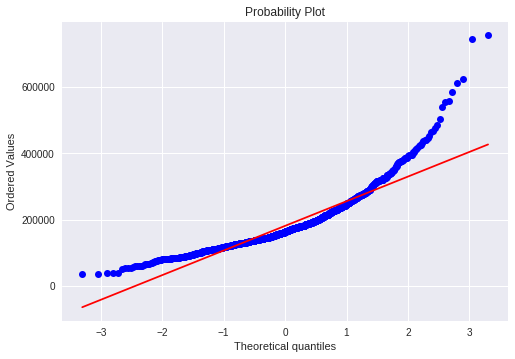
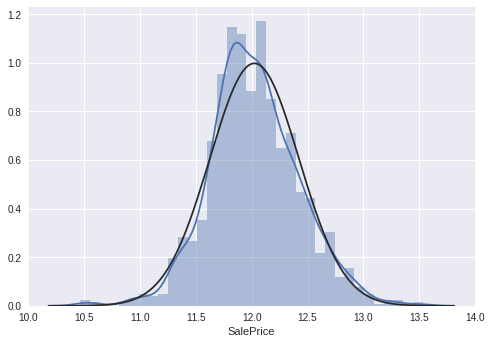
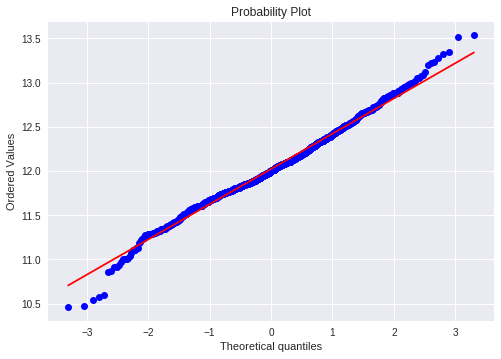
正态分布
用histogram 和 normal probability可以观察数据的峰度偏度以及是否符合正态分布
1 2 3
sns.distplot(df_train['SalePrice'], fit=norm); fig = plt.figure() res = stats.probplot(df_train['SalePrice'], plot=plt)
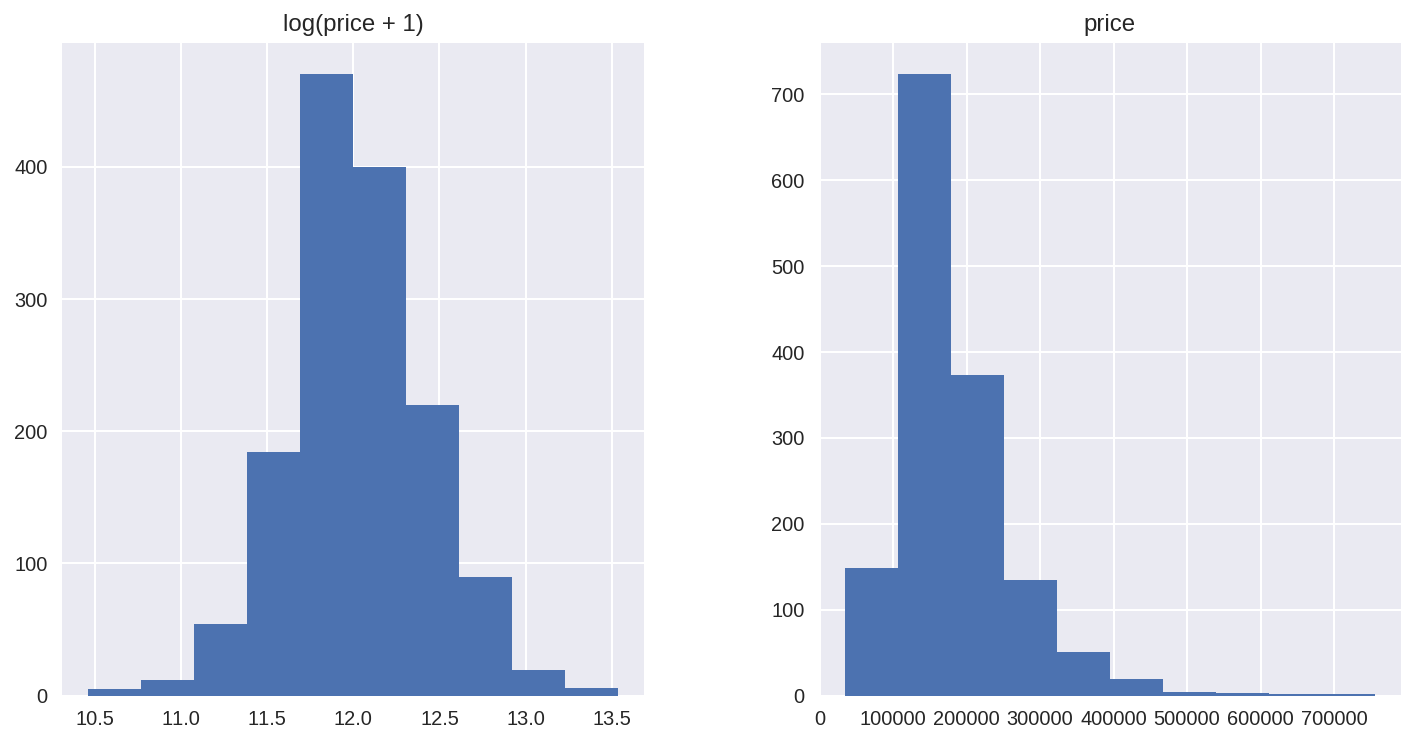
对于正偏度,取log通常不错
1 2 3 4 5 6 7
#applying log transformation df_train['SalePrice'] = np.log(df_train['SalePrice']) In [22]: #transformed histogram and normal probability plot sns.distplot(df_train['SalePrice'], fit=norm); fig = plt.figure() res = stats.probplot(df_train['SalePrice'], plot=plt)
有时我们会遇到具有许多0值得特征,而从istogram 和 normal probability可以看出其具有偏度,那么可以使用如下方法:将非零点取log保留零点。
1 2 3 4 5 6 7 8
#create column for new variable (one is enough because it's a binary categorical feature) #if area>0 it gets 1, for area==0 it gets 0 df_train['HasBsmt'] = pd.Series(len(df_train['TotalBsmtSF']), index=df_train.index) df_train['HasBsmt'] = 0 df_train.loc[df_train['TotalBsmtSF']>0,'HasBsmt'] = 1 In [28]: #transform data df_train.loc[df_train['HasBsmt']==1,'TotalBsmtSF'] = np.log(df_train['TotalBsmtSF'])